
![ApptioCareers-Employee[1]](data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9IjAgMCAyMjUgMjc1IiB3aWR0aD0iMjI1IiBoZWlnaHQ9IjI3NSIgZGF0YS11PSJodHRwcyUzQSUyRiUyRnd3dy5hcHB0aW8uY29tJTJGd3AtY29udGVudCUyRnVwbG9hZHMlMkZlbGVtZW50b3IlMkZ0aHVtYnMlMkZBcHB0aW9DYXJlZXJzLUVtcGxveWVlMS1xZzVuenB5MHdoaWJtbzZvdmJqNGM3MHh0aTUzdmo1OHM0endwajh0dHMucG5nIiBkYXRhLXc9IjIyNSIgZGF0YS1oPSIyNzUiIGRhdGEtYmlwPSIiPjwvc3ZnPg== "ApptioCareers-Employee[1]")
Artificial Intelligence is a hot topic across many fields and industries—and for good reason. It’s transforming everything from product development to customer engagement, unlocking new levels of efficiency and insight. Analyst projections show rapid spending growth with Gartner anticipating that spending on generative AI software will increase by 76% year-over-year, reaching $644 billion by the end of 2025. But with big promises come big risks. Many organizations are already discovering that scaling AI can mean scaling costs even faster—sometimes blowing through budgets long before expected business value materializes.
That’s where FinOps comes in.
From day one, FinOps arose to bring financial accountability to the consumption-based model of public cloud, a novel and dynamic way of provisioning infrastructure compared to what came before. This makes FinOps well-placed to handle the financial challenges posed by GenAI. The vast majority of GenAI runs on public cloud, is therefore charged based on consumption, and comes with the regular array of cloud abstraction options across SaaS, Managed Services and self-managed IaaS.
Let’s explore how FinOps principles apply across the AI lifecycle, using AWS as a practical example.
Understanding Costs Across the GenAI Lifecyle
What’s unique about Generative AI applications? Their development mirrors traditional software in that assets are built and incur ongoing infrastructure costs with use. The distinction lies in the engineering approach: you train the model rather than code its behavior, and the resulting system produces outputs by reasoning probabilistically rather than executing fixed instructions.
Each phase of the GenAI lifecycle has unique cost behaviors and infrastructure characteristics. Understanding these cost phases helps FinOps teams anticipate spend patterns, plan budgets, and apply the right controls at each step.
| Phase | Description | Typical Infrastructure | Cost Characteristics |
|---|---|---|---|
| Building | Data preparation, experimentation, and prototyping | CPU-optimized or small GPU instances | Moderate, steady costs |
| Training | Large-scale model training or fine-tuning | GPU clusters (e.g., NVIDIA A100/H100) | Bursty, high-intensity cost spikes |
| Inference | Serving the model to end users | GPU-backed endpoints or serverless inference | Ongoing, usage-based costs (e.g., per token) |
Leveraging AI Managed Services
As organizations scale their AI initiatives, managed services provide a faster, more controlled path to innovation. They abstract away infrastructure complexity that comes with GPU provisioning, scaling, and optimization, allowing teams to focus on model performance and business outcomes rather than system management.

The diagram shows how Amazon’s two main AI managed services map to these phases. Building and training activities, available via SageMaker, are typically treated as R&D investments that can be capitalized and amortized over time. Inference, available through both SageMaker and Bedrock, typically represents ongoing production costs categorized as COGS or OpEx, where spend scales directly with usage. This distinction helps FinOps teams align AI spend with how value is created and consumed.
Example Scenario: Allocating Team Costs for Amazon SageMaker
For teams developing custom AI models, Amazon SageMaker provides an end-to-end environment for building, training, and deploying at scale. Let’s walk through an example of allocating costs for “Team Owned Infrastructure.”
Regardless of the AI phase, SageMaker charges primarily per instance-hour, using the same underlying EC2 instance families and pricing model. Here is a handy summary of what this infrastructure and pricing looks like:
| Phase | Example Instance Types | Approx. Hourly Rate (USD) | Summary |
|---|---|---|---|
| Building | ml.t3.medium ml.m5.xlarge |
$0.05 $0.23 |
Lightweight compute for data prep, prototyping, and feature engineering in SageMaker Studio or Jupyter notebooks |
| Training | ml.g5.12xlarge ml.p4d.24xlarge |
$7.09 $25.25 |
High-performance GPU clusters for deep learning or LLM fine-tuning; scale up for distributed or large-batch training |
| Inference | ml.m5.large ml.g4dn.xlarge |
$0.12 $0.74 |
Always-on endpoints serving real-time predictions; CPU for lighter models, GPU for generative or vision workloads |
The good news is that, like most AWS services, SageMaker supports resource tagging, allowing costs to be categorized through key-value pairs. In a scenario where an AI application, and its costs, is owned by a single team we can apply standard tagging and account-based allocation to group spend by:
- Team or application
- Environment (e.g., testing vs. production)
- Cost Type (e.g., R&D vs OpEx)
Through IBM Cloudability’s Business Mapping feature, rules can be built around those billing attributes to officially categorize the costs and to fit into automated showback or chargeback processes.
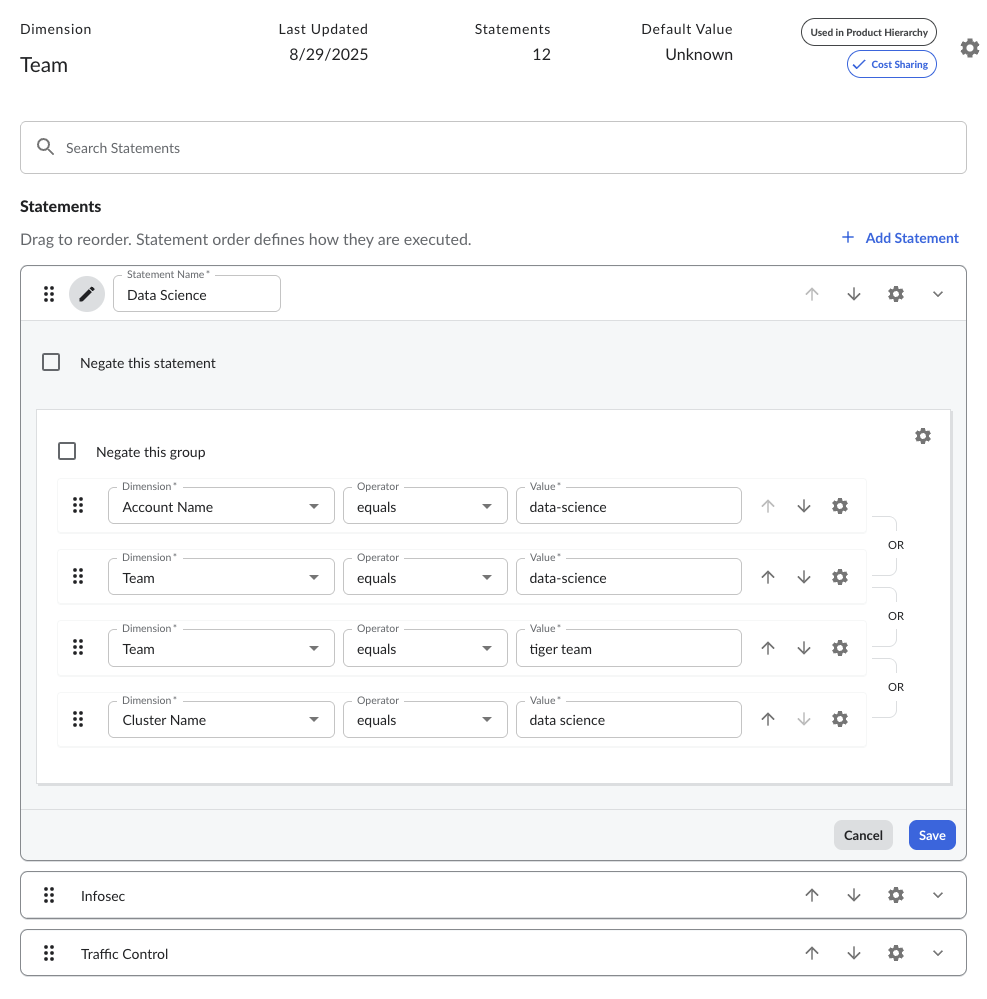
Figure: Example allocation rule with IBM Cloudability Business Mapping
Example Scenario: Allocating Shared Costs for Amazon Bedrock
Where a custom model isn’t required, organizations often rely on foundation models (FMs) from providers like Anthropic, Meta, or Amazon (Nova and Titan) to deliver inference. Amazon Bedrock simplifies this process by offering fully managed, serverless access to foundation models with built-in options for fine-tuning—all without the need to manage infrastructure or scaling manually.
Amazon Bedrock pricing is usage-based rather than instance-based. For example, customers pay per token processed for text and chat models, per image generated for vision models, or per audio request for speech and media workloads.
| Model Category | Examples Models / Providers | Billing Unit | Typical Range (USD) |
|---|---|---|---|
| Text & Chat | Anthropic Claude 3, Meta Llama 3, Amazon Titan Text | Per 1K tokens (input + output) | ~$0.001 – $0.06 per 1K tokens |
| Image Generation | Amazon Titan Image, Stability AI SDXL | Per image generated | ~$0.02 – $0.05 per image |
| Audio & Speech | Models for transcription or audio generation | Per request or minute of audio | ~$0.005 – $0.02 per minute (or request) |
In a scenario where there are multiple consumers or customers of an application, not only do the costs need to be mapped—using tags and accounts as described earlier—but a mechanism must be found to split up the costs to assign them out. Because Bedrock’s serverless pricing is directly tied to consumption, telemetry data such as tokens processed, requests made, or outputs generated provides a precise way to split and assign costs to each consumer.
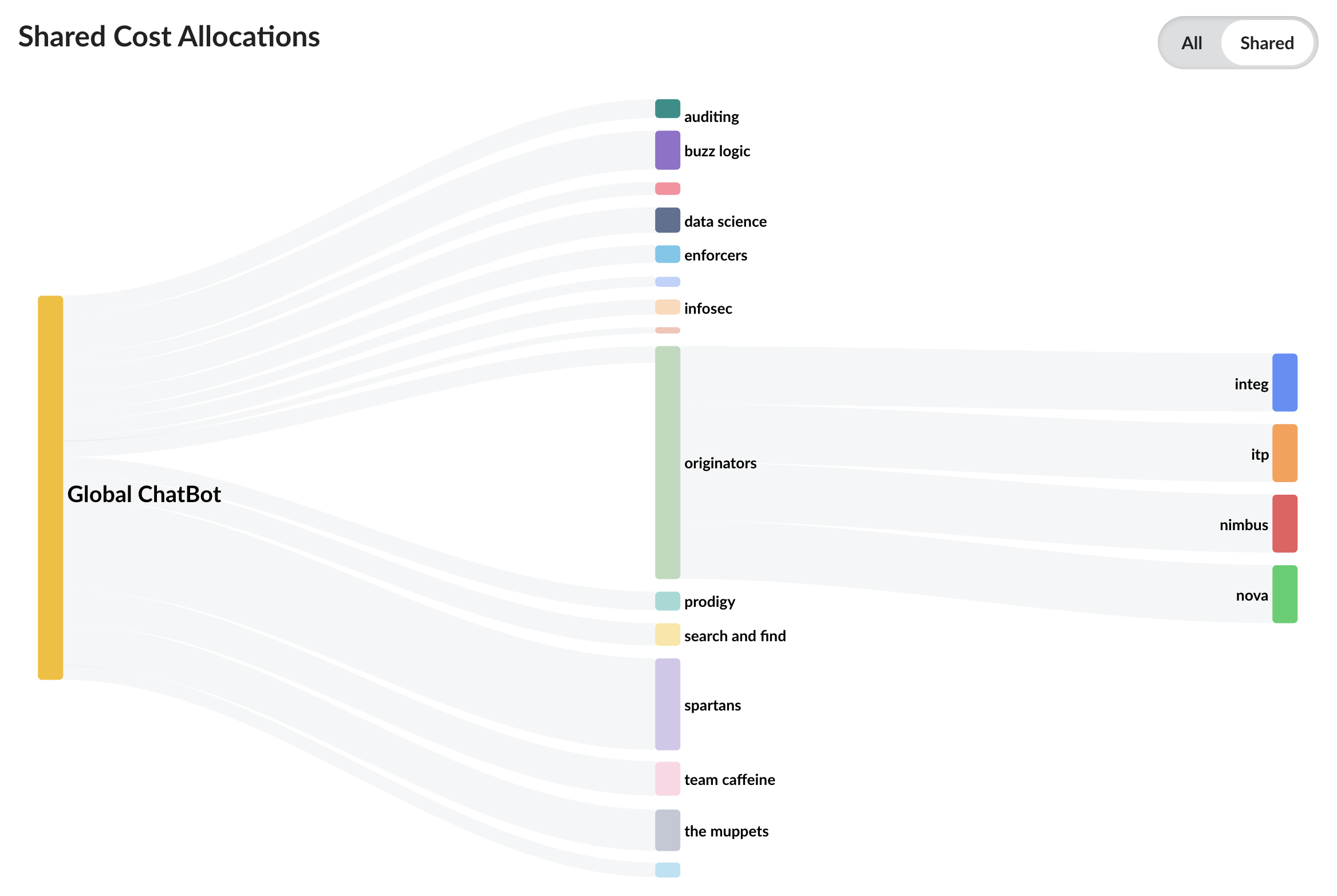
Figure: Using telemetry data to split shared costs in IBM Cloudability
Using IBM Cloudability’s Shared Cost functionality, organizations can map this shared Bedrock spend to end consumers based on actual usage telemetry, ensuring that costs are distributed equitably and transparently across teams, products, or customer accounts.
Bringing It All Together: Unified AI Cost Visibility
Having accurately categorized and allocated these GenAI costs, the next crucial step in achieving financial accountability is to scale cost visibility to all relevant stakeholders, ideally with detailed insights covering the complete picture—across cloud providers, services, and environments.
With IBM Cloudability, everyone can explore GenAI cost and usage data in a single pane of glass. This unified visibility spans managed services such as Amazon SageMaker and Amazon Bedrock, self-managed IaaS infrastructure, and third-party SaaS providers like Anthropic and OpenAI. In dashboards and reports users can include the metrics and dimensions that make the most sense to them, using both out-of-the-box categorization and any custom business dimensions they created earlier for consistent reporting across all AI spend. For example, IT Finance members may prefer to use Cost Type and Chargeback reporting dimensions while engineers instead drill down to the resource level and include token and image counts.
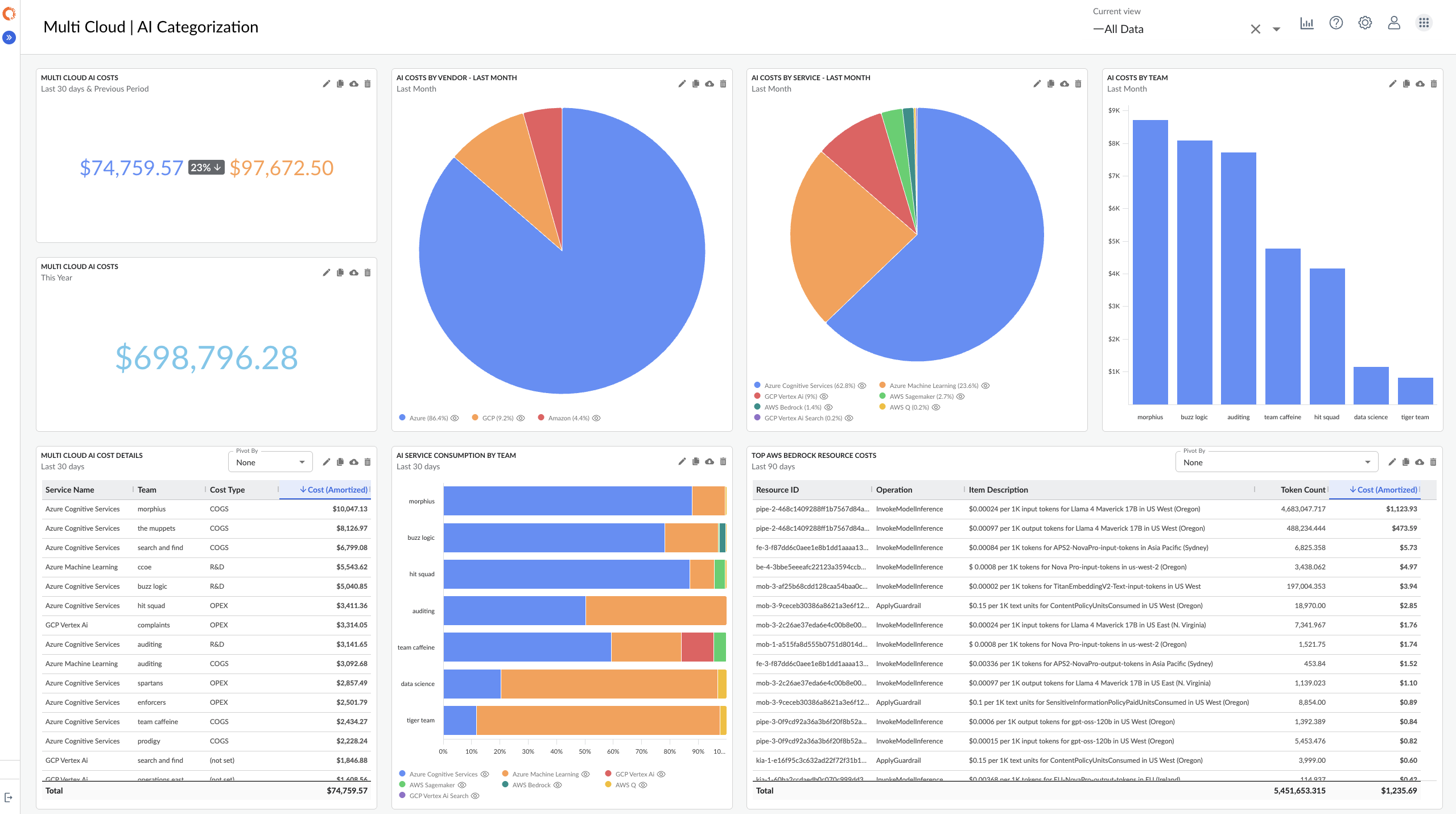
Figure: Example dashboard capturing and categorizing all GenAI spend
Finally, Cloudability Views make the analysis personal and actionable to each stakeholder. Users can filter the entire in-app experience by the team, project, or application that is most relevant to them. Whether managing a centralized AI platform or multiple distributed initiatives, this tailored visibility ensures that every dollar of AI investment is traceable, explainable, and can be aligned to business outcomes. These insights empower engineers, product owners, and finance teams alike—ensuring the right people see the right AI cost data at the right time.
The Future of Managing GenAI
As AI matures, so must the way we manage its costs. To keep up with the fast pace of model development and deployment organizations need adaptive financial planning.
With IBM Cloudability’s forecasting and scenario modeling, FinOps teams can project future AI costs as usage patterns change, while adding human context like retraining plans, new projects, or retiring workloads. This combination of data-driven prediction and human foresight leads to financial alignment and realistic budgets.
At the same time, success in AI FinOps depends on understanding unit economics—linking cost to business value at the level of tokens, inferences, or outcomes. Without this connection, AI risks becoming the most expensive experiment in IT history. By extending FinOps disciplines to AI workloads, organizations can innovate confidently while maintaining control.
With Cloudability, FinOps teams don’t just track AI costs—they turn them into strategic insights that align investment with value, drive better decisions, and keep innovation on budget.
Stay tuned for upcoming posts as we explore deeper practices in AI cost forecasting, optimization and unit economics.


