
![ApptioCareers-Employee[1]](data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9IjAgMCAyMjUgMjc1IiB3aWR0aD0iMjI1IiBoZWlnaHQ9IjI3NSIgZGF0YS11PSJodHRwcyUzQSUyRiUyRnd3dy5hcHB0aW8uY29tJTJGd3AtY29udGVudCUyRnVwbG9hZHMlMkZlbGVtZW50b3IlMkZ0aHVtYnMlMkZBcHB0aW9DYXJlZXJzLUVtcGxveWVlMS1xZzVuenB5MHdoaWJtbzZvdmJqNGM3MHh0aTUzdmo1OHM0endwajh0dHMucG5nIiBkYXRhLXc9IjIyNSIgZGF0YS1oPSIyNzUiIGRhdGEtYmlwPSIiPjwvc3ZnPg== "ApptioCareers-Employee[1]")
The challenges
Apptio Kubernetes Platform (AKP) hosts many different types of workloads, both static and transient in nature. At Apptio, we allocate Dedicated Hosts for the steady-state workload and rely on Spot instances for the transient workloads. Dedicated Hosts help with CapEx and make our cloud compute spend more predictable for the year, assuming these Dedicated Hosts are fully used, which turned out to be non-trivial. There were multiple reasons why our Dedicated Hosts ended up underutilized. We have a lot of smaller, more transient workloads that would sneak in onto the large Dedicated Hosts. The largest static workloads required r5.8xlarge instances, but AWS did not support them on r5. That meant we had to fill the excess with r5.4xlarge. Initially these workloads were relatively few, and we deployed them to On-Demand hosts, even though there was room for them on the Dedicated Host fleet. Eventually, the largest workloads grew in number and the associated rise in the On-Demand cost became hard to ignore. Finally, we lacked a robust policy engine to make the allocation of workloads more efficient.
Many nodes ended up being utilized at just 60% or 70%. Subsequently, the hosting density decreased even more due to planned and unplanned restarts of the workloads. Although we had good control over which instance types the Cluster Autoscaler would scale up, we did not have the equivalent control of the scheduling of pods onto nodes that had already been provisioned. Following the restarts, some workloads that were supposed to run on the Dedicated Hosts ended up on the On-Demand instances. In other words, we were underusing the services that we paid for, and we were wasting money on the unplanned On-Demand spend. Another downside was that our total number of nodes on the platform was unreasonably high. The high number of nodes has several drawbacks. Management overhead was one. Another was related to third-party vendor costs. Many vendors, like Datadog, for example, charge per node. We have about 3k production nodes instrumented with Datadog agent and about 75% of them also have Application Performance Monitoring (APM). The associated cost was not insignificant. Increasing the instance size of some node groups in our clusters would mean fewer nodes, a potentially better hosting density and a lower Datadog bill.
The actual challenge was to implement policies by which certain workloads, based on their resource constraints and purpose, would reliably go to specialized node groups with different underlying instance sizes.
Historically, we have been using Gatekeeper to manage policies. Along with several benefits, Gatekeeper has limitations, e.g., a steep learning curve of the rego language and limited support for mutations.
To address the shortcomings, we turned our attention to Kyverno, which would give us some extra control to modify the pod node selectors when they launch.
Kyverno
The initial rollout of Kyverno coincided with the rollout of larger EC2 instances to accommodate more resource demanding workloads and focused on improving the hosting density of other workloads simply because they could better fit into the larger instance. New Kyverno policies would apply to specially designated services of our flagship application and ensure their placement on the larger instances. For this purpose, we chose r5.12xlarge instead of the traditionally used r5.4xlarge and r5.8xlarge.
To introduce r5.12xlarge instances, we had to be mindful of several constraints.
AWS imposes a limit of 25 EBS volumes on Nitro instance types, which includes R5. This means if we were to allow pods smaller than a certain size to run on the r5.12xlarge instances, we would be risking not being able to fill them up because of the EBS volume limit and accumulating wasted capacity; in which case, we need to deal with smaller pods differently.
The flagship application also has several more ephemeral services used for data processing. They are not static by nature and are regularly being created and destroyed. If we used such a large instance type to host these workloads, we would be running the risk of significant fragmentation and wastage. This means we needed a different approach for the data processing pods, too.
Solution
We ended up with the following policy setup:
All steady-state services of the flagship application, which included web applications and web services deployments, are scheduled to the r5.12xlarge or r5.4xlarge instance types, depending on the size of their memory requests.
Pods requesting less than 40 GB are scheduled onto r5.4xlarge instances only. These instances will not be provided on Dedicated Hosts, only On-Demand instances. Placing them on these instances ensures that the 25 x EBS volume limit is not exceeded on the r5.12xlarges. The percentage of pods that are this small size is relatively low, making this approach the most optimal.
Pods requesting 40 GB or more are placed onto the r5.12.xlarge instances only. These instances can be on Dedicated Hosts or On-Demand instances, depending on the available Dedicated Host capacity. Soft affinity rules are in place to make these pods prefer Dedicated Host instances over On-Demand instances at the scheduling time.
All ephemeral data processing pods are scheduled to r5.4xlarge or r5.8xlarge instance types that are either On-Demand instances or Spot. We explicitly want to avoid hosting these workloads on the Dedicated Hosts to reduce the fragmentation of the Dedicated Host capacity. The r5.8xlarge will only be scaled up if a pod requires a larger size, otherwise r5.4xlarge will be used. This reduces the amount of fragmentation and allows instances to be churned more frequently. Separate instance groups are provisioned for this purpose with a designated label and an associated taint to prevent the other more static workloads from running on them.
The results
After these Kyverno policies were introduced, the hosting density and the utilization of Dedicated Hosts increased to 100%.

As shown above, our total number of nodes for just the flagship application went down from 1500 to 1000, with a pleasant side effect of Datadog monthly bill decreasing by 14%.
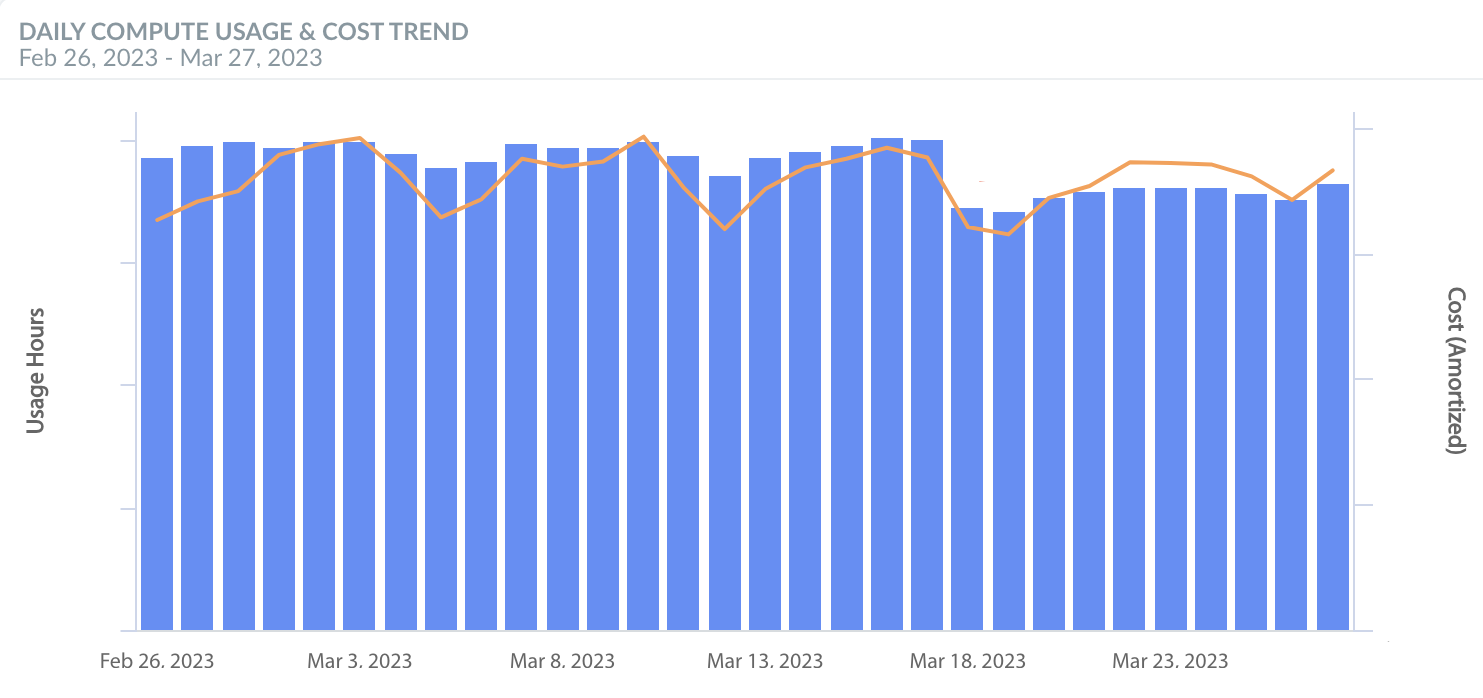
Most importantly, our unplanned On-Demand spend went down by $3k/day, i.e., 10% in savings. As part of our broader observability practice, we track our cloud hosting spend using our own tool, Cloudability. The decrease in the On-Demand spending is shown on this Cloudability chart.




